Deployer
原文地址 : alibaba/canal/wiki/AdminGuide
部署
1. 获取发布包
方法1: (直接下载)访问:alibaba/canal/tree/gh-pages/download ,会列出所有历史的发布版本包下载方式,比如以1.0.4版本为例子:
$ wget https://raw.github.com/alibaba/canal/gh-pages/download/canal.deployer-1.0.4.tar.gz方法2: (自己编译)
git clone git@github.com:alibaba/canal.git
git co canal-$version #切换到对应的版本上
mvn clean install -Denv=release执行完成后,会在canal工程根目录下生成一个target目录,里面会包含一个 canal.deployer-$verion.tar.gz
2. 目录结构
解压缩发布包后,可得如下目录结构:
drwxr-xr-x 2 jianghang jianghang 136 2013-03-19 15:03 bin
drwxr-xr-x 4 jianghang jianghang 160 2013-03-19 15:03 conf
drwxr-xr-x 2 jianghang jianghang 1352 2013-03-19 15:03 lib
drwxr-xr-x 2 jianghang jianghang 48 2013-03-19 15:03 logs3. 启动/停止
linux启动 :
sh startup.shlinux带debug方式启动:(默认使用suspend=y,阻塞等待你remote debug链接成功)
sh startup.sh debug 9099linux停止:
sh stop.sh几点注意:
- linux启动完成后,会在bin目录下生成canal.pid,stop.sh会读取canal.pid进行进程关闭
- startup.sh默认读取系统环境变量中的which java获得JAVA执行路径,需要设置PATH=$JAVA_HOME/bin环境变量
windows启动:(windows支持相对比较弱)
startup.batwindows停止:直接关闭终端即可
配置
介绍配置之前,先了解下canal的配置加载方式:
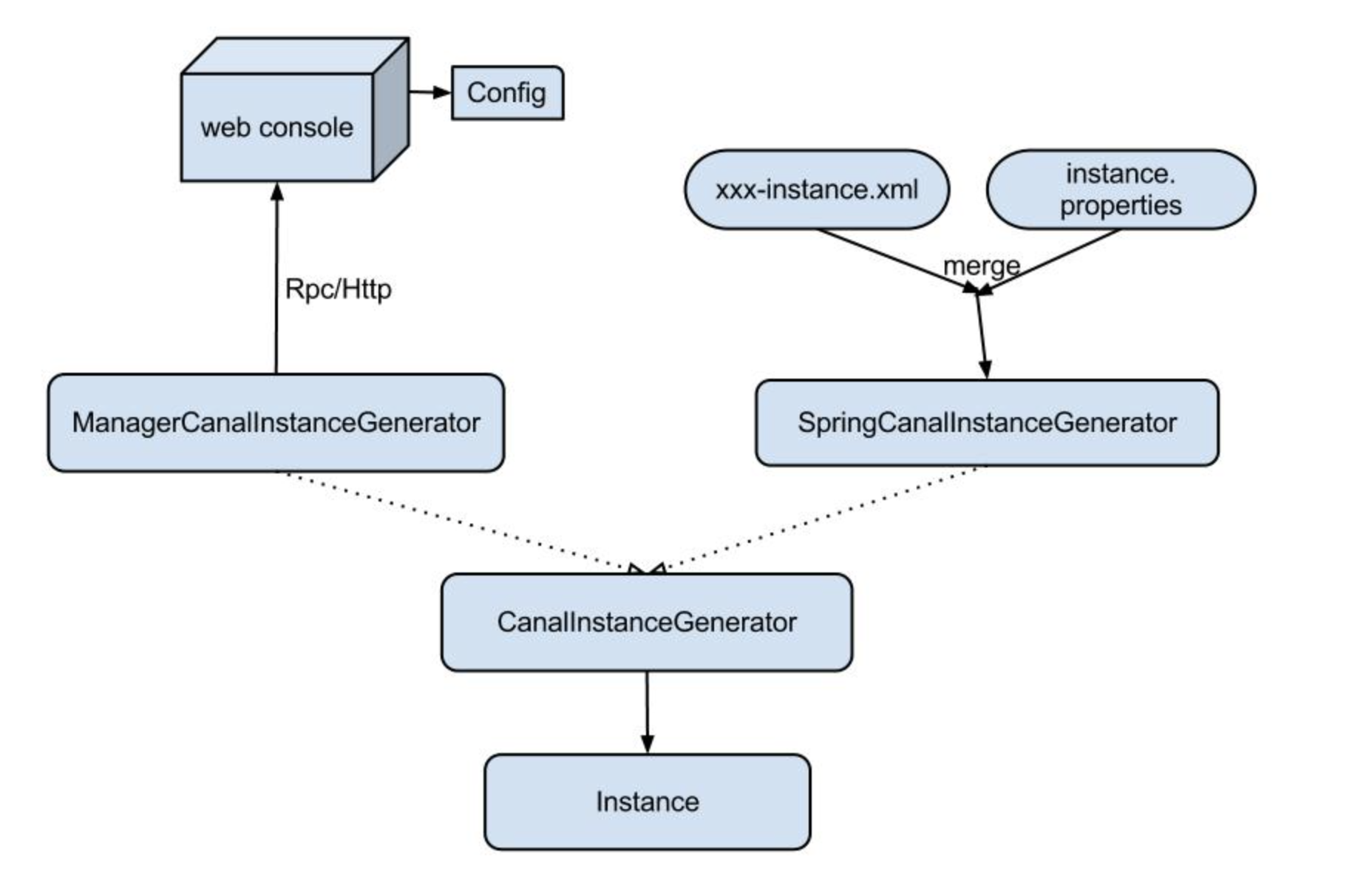
canal配置方式有两种:
- ManagerCanalInstanceGenerator: 基于manager管理的配置方式,目前alibaba内部配置使用这种方式。大家可以实现CanalConfigClient,连接各自的管理系统,即可完成接入。
- SpringCanalInstanceGenerator:基于本地spring xml的配置方式,目前开源版本已经自带该功能所有代码,建议使用
Spring配置
spring配置的原理是将整个配置抽象为两部分:
- xxxx-instance.xml (canal组件的配置定义,可以在多个instance配置中共享)
- xxxx.properties (每个instance通道都有各自一份定义,因为每个mysql的ip,帐号,密码等信息不会相同)
通过spring的 PropertyPlaceholderConfigurer 通过机制将其融合,生成一份instance实例对象,每个instance对应的组件都是相互独立的,互不影响
properties配置文件
properties配置分为两部分:
- canal.properties (系统根配置文件)
- instance.properties (instance级别的配置文件,每个instance一份)
canal.properties介绍: canal配置主要分为两部分定义:
- instance列表定义 (列出当前server上有多少个instance,每个instance的加载方式是spring/manager等)
| 参数名字 | 参数说明 | 默认值 |
| canal.destinations | 当前server上部署的instance列表 | 无 |
| canal.conf.dir | conf/目录所在的路径 | ../conf |
| canal.auto.scan | 开启instance自动扫描 | true |
| canal.auto.scan.interval | instance自动扫描的间隔时间,单位秒 | 5 |
| canal.instance.global.mode | 全局配置加载方式 | spring |
| canal.instance.global.lazy | 全局lazy模式 | false |
| canal.instance.global.manager.address | 全局的 manager 配置方式的链接信息 | 无 |
| canal.instance.global.spring.xml | 全局的spring配置方式的组件文件 | classpath:spring/memory-instance.xml |
| canal.instance.example.mode | instance级别的配置定义,如有配置,会自动覆盖全局配置定义模式 | 无 |
| canal.instance.tsdb.spring.xml | v1.0.25版本新增,全局的tsdb配置方式的组件文件 | classpath:spring/tsdb/h2-tsdb.xml (spring目录相对于canal.conf.dir) |
- common参数定义,比如可以将instance.properties的公用参数,抽取放置到这里,这样每个instance启动的时候就可以共享. 【instance.properties配置定义优先级高于canal.properties】
| 参数名字 | 参数说明 | 默认值 |
| canal.id | 每个canal server实例的唯一标识,暂无实际意义 | 1 |
| canal.ip | canal server绑定的本地IP信息,如果不配置,默认选择一个本机IP进行启动服务 | 无 |
| canal.register.ip | canal server注册到外部zookeeper、admin的ip信息 (针对docker的外部可见ip) | 无 |
| canal.port | canal server 提供 socket 服务的端口 | 11111 |
| canal.zkServers | canal server链接zookeeper集群的链接信息 | 无 |
| canal.zookeeper.flush.period | canal持久化数据到zookeeper上的更新频率,单位毫秒 | 1000 |
| canal.instance.memory.batch.mode | canal内存store中数据缓存模式 | MEMSIZE |
| canal.instance.memory.buffer.size | canal内存store中可缓存buffer记录数,需要为2的指数 | 16384 |
| canal.instance.memory.buffer.memunit | 内存记录的单位大小,默认1KB,和buffer.size组合决定最终的内存使用大小 | 1024 |
| canal.instance.transactionn.size | 最大事务完整解析的长度支持 | 1024 |
| canal.instance.fallbackIntervalInSeconds | canal发生mysql切换时,在新的mysql库上查找binlog时需要往前查找的时间,单位秒 | 60 |
| canal.instance.detecting.enable | 是否开启心跳检查 | false |
| canal.instance.detecting.sql | 心跳检查sql | insert into retl.xdual values(1,now()) on duplicate key update x=now() |
| canal.instance.detecting.interval.time | 心跳检查频率,单位秒 | 3 |
| canal.instance.detecting.retry.threshold | 心跳检查失败重试次数 | 3 |
| canal.instance.detecting.heartbeatHaEnable | 心跳检查失败后,是否开启自动mysql自动切换 | false |
| canal.instance.network.receiveBufferSize | 网络链接参数,SocketOptions.SO_RCVBUF | 16384 |
| canal.instance.network.sendBufferSize | 网络链接参数,SocketOptions.SO_SNDBUF | 16384 |
| canal.instance.network.soTimeout | 网络链接参数,SocketOptions.SO_TIMEOUT | 30 |
| canal.instance.filter.druid.ddl | 是否使用druid处理所有的ddl解析来获取库和表名 | true |
| canal.instance.filter.query.dcl | 是否忽略dcl语句 | false |
| canal.instance.filter.query.dml | 是否忽略dml语句 | false |
| canal.instance.filter.query.ddl | 是否忽略ddl语句 | false |
| canal.instance.filter.table.error | 是否忽略binlog表结构获取失败的异常 | false |
| canal.instance.filter.rows | 是否dml的数据变更事件 | false |
| canal.instance.filter.transaction.entry | 是否忽略事务头和尾,比如针对写入kakfa的消息时,不需要写入TransactionBegin/Transactionend事件 | false |
| canal.instance.binlog.format | 支持的binlog format格式列表 | ROW,STATEMENT,MIXED |
| canal.instance.binlog.image | 支持的binlog image格式列表 | FULL,MINIMAL,NOBLOB |
| canal.instance.get.ddl.isolation | ddl语句是否单独一个batch返回 | false |
| canal.instance.parser.parallel | 是否开启binlog并行解析模式 | true |
| canal.instance.parser.parallelBufferSize | binlog并行解析的异步ringbuffer队列 | 256 |
| canal.instance.tsdb.enable | 是否开启tablemeta的tsdb能力 | true |
| canal.instance.tsdb.dir | 主要针对h2-tsdb.xml时对应h2文件的存放目录,默认为conf/xx/h2.mv.db | c |
| canal.instance.tsdb.url | jdbc url的配置 | jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL; |
| canal.instance.tsdb.dbUsername | jdbc url的配置 | canal |
| canal.instance.tsdb.dbPassword | jdbc url的配置 | canal |
| canal.instance.rds.accesskey | aliyun账号的ak信息 | 无 |
| canal.instance.rds.secretkey | aliyun账号的sk信息 | 无 |
| canal.admin.manager | canal链接canal-admin的地址 (v1.1.4新增) | 无 |
| canal.admin.port | admin管理指令链接端口 (v1.1.4新增) | 11110 |
| canal.admin.user | admin管理指令链接的ACL配置 (v1.1.4新增) | admin |
| canal.admin.passwd | admin管理指令链接的ACL配置 (v1.1.4新增) | 密码默认值为admin的密文 |
| canal.user | canal数据端口订阅的ACL配置 (v1.1.4新增) | 无 |
| canal.passwd | canal数据端口订阅的ACL配置 (v1.1.4新增) | 无 |
instance.properties介绍:
- 在canal.properties定义了canal.destinations后,需要在
canal.conf.dir对应的目录下建立同名的文件比如:
canal.destinations = example1,example2这时需要创建example1和example2两个目录,每个目录里各自有一份instance.properties.
ps. canal自带了一份instance.properties demo,可直接复制conf/example目录进行配置修改
cp -R example example1/
cp -R example example2/如果canal.properties未定义instance列表,但开启了canal.auto.scan时
server第一次启动时,会自动扫描conf目录下,将文件名做为instance name,启动对应的instance
server运行过程中,会根据canal.auto.scan.interval定义的频率,进行扫描1. 发现目录有新增,启动新的instance2. 发现目录有删除,关闭老的instance3. 发现对应目录的instance.properties有变化,重启instance
一个标准的conf目录结果:
jianghang@jianghang-laptop:~/work/canal/deployer/target/canal$ ls -l conf/
总用量 8
-rwxrwxrwx 1 jianghang jianghang 1677 2013-03-19 15:03 canal.properties ##系统配置
drwxr-xr-x 2 jianghang jianghang 88 2013-03-19 15:03 example ## instance配置
-rwxrwxrwx 1 jianghang jianghang 1840 2013-03-19 15:03 logback.xml ## 日志文件
drwxr-xr-x 2 jianghang jianghang 168 2013-03-19 17:04 spring ## spring instance目录instance.properties参数列表:
| 参数名字 | 参数说明 | 默认值 |
| canal.instance.mysql.slaveId | mysql集群配置中的serverId概念,需要保证和当前mysql集群中id唯一 | 无 |
| canal.instance.master.address | mysql主库链接地址 | 127.0.0.1:3306 |
| canal.instance.master.journal.name | mysql主库链接时起始的binlog文件 | 无 |
| canal.instance.master.position | mysql主库链接时起始的binlog偏移量 | 无 |
| canal.instance.master.timestamp | mysql主库链接时起始的binlog的时间戳 | 无 |
| canal.instance.gtidon | 是否启用mysql gtid的订阅模式 | false |
| canal.instance.master.gtid | mysql主库链接时对应的gtid位点 | 无 |
| canal.instance.dbUsername | mysql数据库帐号 | canal |
| canal.instance.dbPassword | mysql数据库密码 | canal |
| canal.instance.defaultDatabaseName | mysql链接时默认schema | |
| canal.instance.connectionCharset | mysql 数据解析编码 | UTF-8 |
| canal.instance.filter.regex | mysql 数据解析关注的表,Perl正则表达式. |
常见例子:
所有表:.* or . \..
canal schema下所有表: canal\..
3. canal下的以canal打头的表:canal\.canal.
canal schema下的一张表:canal\.test1
多个规则组合使用:canal\.. ,mysql.test1,mysql.test2 (逗号分隔) | . \..*
| canal.instance.filter.black.regex | mysql 数据解析表的黑名单,表达式规则见白名单的规则 | 无 |
| canal.instance.rds.instanceId | 无 |
几点说明:
mysql链接时的起始位置
canal.instance.master.journal.name + canal.instance.master.position : 精确指定一个binlog位点,进行启动
canal.instance.master.timestamp : 指定一个时间戳,canal会自动遍历mysql binlog,找到对应时间戳的binlog位点后,进行启动
不指定任何信息:默认从当前数据库的位点,进行启动。(show master status)
mysql解析关注表定义
标准的Perl正则,注意转义时需要双斜杠:\
mysql链接的编码
目前canal版本仅支持一个数据库只有一种编码,如果一个库存在多个编码,需要通过filter.regex配置,将其拆分为多个canal instance,为每个instance指定不同的编码
instance.xml配置文件
目前默认支持的instance.xml有以下几种:
- spring/memory-instance.xml
- spring/default-instance.xml
- spring/group-instance.xml
在介绍instance配置之前,先了解一下canal如何维护一份增量订阅&消费的关系信息:
- 解析位点 (parse模块会记录,上一次解析binlog到了什么位置,对应组件为:CanalLogPositionManager)
- 消费位点 (canal server在接收了客户端的ack后,就会记录客户端提交的最后位点,对应的组件为:CanalMetaManager)
对应的两个位点组件,目前都有几种实现:
- memory (memory-instance.xml中使用)
- zookeeper
- mixed
- period (default-instance.xml中使用,集合了zookeeper+memory模式,先写内存,定时刷新数据到zookeeper上)
memory-instance.xml介绍:
所有的组件(parser , sink , store)都选择了内存版模式,记录位点的都选择了memory模式,重启后又会回到初始位点进行解析
特点:速度最快,依赖最少(不需要zookeeper)
场景:一般应用在quickstart,或者是出现问题后,进行数据分析的场景,不应该将其应用于生产环境
default-instance.xml介绍:
store选择了内存模式,其余的parser/sink依赖的位点管理选择了持久化模式,目前持久化的方式主要是写入zookeeper,保证数据集群共享.
特点:支持HA场景:生产环境,集群化部署.
group-instance.xml介绍:
主要针对需要进行多库合并时,可以将多个物理instance合并为一个逻辑instance,提供客户端访问。
场景:分库业务。 比如产品数据拆分了4个库,每个库会有一个instance,如果不用group,业务上要消费数据时,需要启动4个客户端,分别链接4个instance实例。使用group后,可以在canal server上合并为一个逻辑instance,只需要启动1个客户端,链接这个逻辑instance即可.
instance.xml设计初衷:
允许进行自定义扩展,比如实现了基于数据库的位点管理后,可以自定义一份自己的instance.xml,整个canal设计中最大的灵活性在于此
HA模式配置
- 机器准备a. 运行canal的机器: 10.20.144.22 , 10.20.144.51.b. zookeeper地址为10.20.144.51:2181c. mysql地址:10.20.144.15:33062. 按照部署和配置,在单台机器上各自完成配置,演示时instance name为example
- 修改canal.properties,加上zookeeper配置
canal.zkServers=10.20.144.51:2181
canal.instance.global.spring.xml = classpath:spring/default-instance.xml- 创建example目录,并修改instance.properties
canal.instance.mysql.slaveId = 1234 ##另外一台机器改成1235,保证slaveId不重复即可
canal.instance.master.address = 10.20.144.15:3306注意: 两台机器上的instance目录的名字需要保证完全一致,HA模式是依赖于instance name进行管理,同时必须都选择default-instance.xml配置
- 启动两台机器的canal
-------
ssh 10.20.144.51
sh bin/startup.sh
--------
ssh 10.20.144.22
sh bin/startup.sh启动后,你可以查看logs/example/example.log,只会看到一台机器上出现了启动成功的日志。
比如我这里启动成功的是10.20.144.51
2013-03-19 18:18:20.590 [main] INFO c.a.o.c.i.spring.support.PropertyPlaceholderConfigurer - Loading properties file from class path resource [canal.properties]
2013-03-19 18:18:20.596 [main] INFO c.a.o.c.i.spring.support.PropertyPlaceholderConfigurer - Loading properties file from class path resource [example/instance.properties]
2013-03-19 18:18:20.831 [main] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start CannalInstance for 1-example
2013-03-19 18:18:20.845 [main] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start successful...查看一下zookeeper中的节点信息,也可以知道当前工作的节点为10.20.144.51:11111
[zk: localhost:2181(CONNECTED) 15] get /otter/canal/destinations/example/running
{"active":true,"address":"10.20.144.51:11111","cid":1}- 客户端链接, 消费数据
- 可以直接指定zookeeper地址和instance name,canal client会自动从zookeeper中的running节点,获取当前服务的工作节点,然后与其建立链接:
CanalConnector connector = CanalConnectors.newClusterConnector("10.20.144.51:2181", "example", "", "");- 链接成功后,canal server会记录当前正在工作的canal client信息,比如客户端ip,链接的端口信息等 (聪明的你,应该也可以发现,canal client也可以支持HA功能)
[zk: localhost:2181(CONNECTED) 17] get /otter/canal/destinations/example/1001/running
{"active":true,"address":"10.12.48.171:50544","clientId":1001}- 数据消费成功后,canal server会在zookeeper中记录下当前最后一次消费成功的binlog位点. (下次你重启client时,会从这最后一个位点继续进行消费)
[zk: localhost:2181(CONNECTED) 16] get /otter/canal/destinations/example/1001/cursor
{"@type":"com.alibaba.otter.canal.protocol.position.LogPosition","identity":{"slaveId":-1,"sourceAddress":{"address":"10.20.144.15","port":3306}},"postion":{"included":false,"journalName":"mysql-bin.002253","position":2574756,"timestamp":1363688722000}}- 重启一下canal server
停止正在工作的10.20.144.51的canal server
ssh 10.20.144.51
sh bin/stop.sh这时10.20.144.22会立马启动example instance,提供新的数据服务
[zk: localhost:2181(CONNECTED) 19] get /otter/canal/destinations/example/running
{"active":true,"address":"10.20.144.22:11111","cid":1}与此同时,客户端也会随着canal server的切换,通过获取zookeeper中的最新地址,与新的canal server建立链接,继续消费数据,整个过程自动完成
触发HA自动切换场景 (server/client HA模式都有效)
- 正常场景
- 正常关闭canal server(会释放instance的所有资源,包括删除running节点)
- 平滑切换(gracefully)
操作:更新对应instance的running节点内容,将“active”设置为false,对应的running节点收到消息后,会主动释放running节点,让出控制权但自己jvm不退出,gracefully.
{"active":false,"address":"10.20.144.22:11111","cid":1}- 异常场景
- canal server对应的jvm异常crash,running节点的释放会在对应的zookeeper session失效后,释放running节点(EPHEMERAL节点)
ps. session过期时间默认为zookeeper配置文件中定义的tickTime的20倍,如果不改动zookeeper配置,那默认就是40秒
- canal server所在的网络出现闪断,导致zookeeper认为session失效,释放了running节点,此时canal server对应的jvm并未退出,(一种假死状态,非常特殊的情况)
ps. 为了保护假死状态的canal server,避免因瞬间runing失效导致instance重新分布,所以做了一个策略:canal server在收到running节点释放后,延迟一段时间抢占running,原本running节点的拥有者可以不需要等待延迟,优先取得running节点,可以保证假死状态下尽可能不无谓的释放资源。 目前延迟时间的默认值为5秒,即running节点针对假死状态的保护期为5秒.
mysql多节点解析配置(parse解析自动切换)
- mysql机器准备
准备两台mysql机器,配置为M-M模式,比如ip为:10.20.144.25:3306,10.20.144.29:3306
[mysqld]
xxxxx ##其他正常master/slave配置
log_slave_updates=true ##这个配置一定要打开- canal instance配置
# position info
canal.instance.master.address = 10.20.144.25:3306
canal.instance.master.journal.name =
canal.instance.master.position =
canal.instance.master.timestamp =
canal.instance.standby.address = 10.20.144.29:3306
canal.instance.standby.journal.name =
canal.instance.standby.position =
canal.instance.standby.timestamp =
##detecing config
canal.instance.detecting.enable = true ## 需要开启心跳检查
canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now() ##心跳检查sql,也可以选择类似select 1的query语句
canal.instance.detecting.interval.time = 3 ##心跳检查频率
canal.instance.detecting.retry.threshold = 3 ## 心跳检查失败次数阀值,超过该阀值后会触发mysql链接切换,比如切换到standby机器上继续消费binlog
canal.instance.detecting.heartbeatHaEnable = true ## 心跳检查超过失败次数阀值后,是否开启master/standby的切换.注意:
- 填写master/standby的地址和各自的起始binlog位置,目前配置只支持一个standby配置.
- 发生master/standby的切换的条件:(heartbeatHaEnable = true) && (失败次数>=retry.threshold).
- 多引入一个heartbeatHaEnable的考虑:开启心跳sql有时候是为client检测canal server是否正常工作,如果定时收到了心跳语句,那说明整个canal server工作正常
- 启动 & 测试
比如关闭一台机器的mysql , /etc/init.d/mysql stop 。在经历大概 interval.time * retry.threshold时间后,就会切换到standby机器上